
数据挖掘-欠拟合与过拟合
以MATLAB 模拟离散点
以下为欠拟合与过拟合图示:
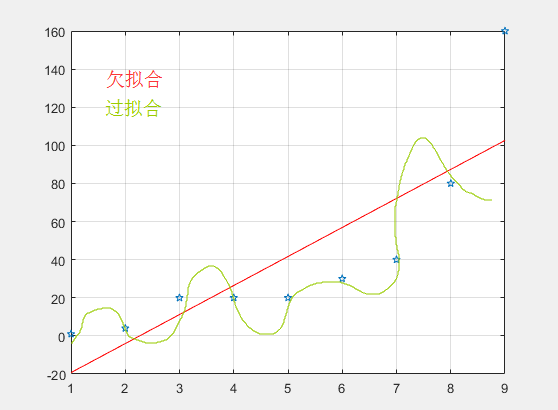
欠拟合
模型没有很好地捕捉到数据特征,不能够很好地拟合数据。
解决方法
- 添加其他特征项,有时候我们模型出现欠拟合的时候是因为特征项不够导致的,可以添加其他特征项来很好地解决。
- 添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强。
- 减少正则化参数,正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,则需要减少正则化参数。
过拟合
模型数据学习过于彻底,噪声数据特征也学习了,后期测试无法很好地识别数据,不能正确的分类,模型泛化能力太差。
解决方法
重新清洗数据,导致过拟合的一个原因也有可能是数据不纯导致的,如果出现了过拟合就需要我们重新清洗数据。
增大数据的训练量,还有一个原因就是我们用于训练的数据量太小导致的,训练数据占总数据的比例过小。
- 标题: 数据挖掘-欠拟合与过拟合
- 作者: Spike Zhang
- 创建于 : 2017-03-08 22:10:14
- 更新于 : 2024-07-13 09:46:17
- 链接: https://chaosbynn.github.io/2017/03/08/数据挖掘-欠拟合与过拟合/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
评论