
数据挖掘-SVM
SVM:寻找一条最优的分界线使得它到两边的距离 margin 都最大。
| 属性 | 描述 |
|---|---|
| 优点 | 泛化错误率低,计算开销不大,易于理解 |
| 缺点 | 对参数调节和核函数选择敏感,原始分类器不参加修改适合处理二类问题 |
| 适用 | 数值型,标称型 |
名词概念
| 名词 | 意义 |
|---|---|
| data | 数据 |
| classifier | 分类器 |
| optimization | 最优解 |
| kernel | 核函数 |
| hyperplane | 超平面 |
SVM - Support Vector Machine 支持向量机,为一种有监督机器(supervised learning)算法,属于分类(classification)的范畴。在数据挖掘的应用中,与无监督(unsupervised)的聚类(Clustering)相对应和区别。
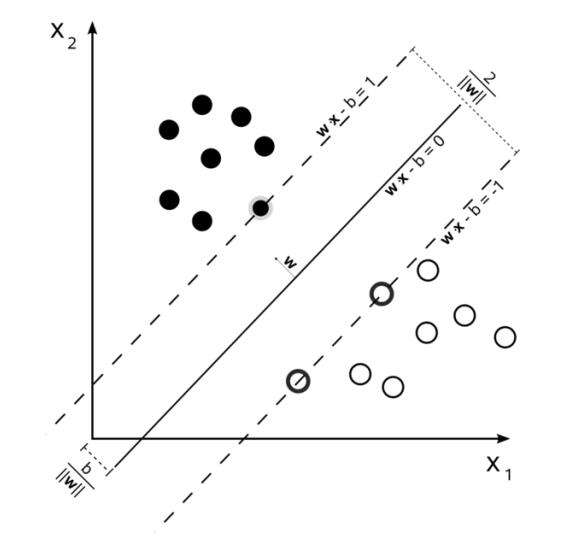
在这种情况下边缘加粗的几个数据点就叫做 Support Vector。
核函数
在二维平面上可用一个线性函数可以将两类样本完全分开叫做线性可分。
事实上,大部分数据并不是线性可分的,这个时候满足这样条件的超平面就根本不存在。对于非线性的情况,SVM 的处理方法是选择一个核函数(Kernel) ,通过将数据映射到高维空间,
拓展至任意n维乃至无限维空间,来解决在原始空间中线性不可分的问题。
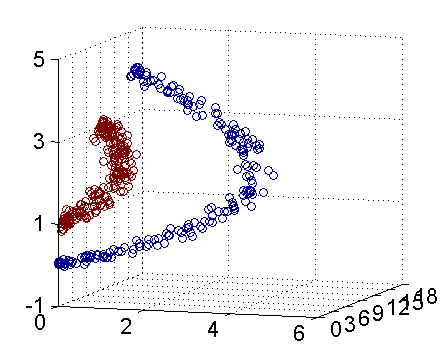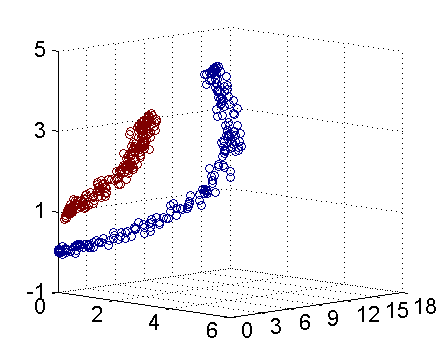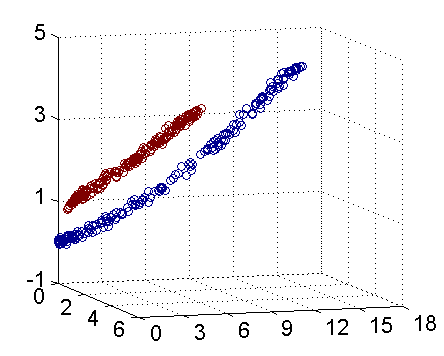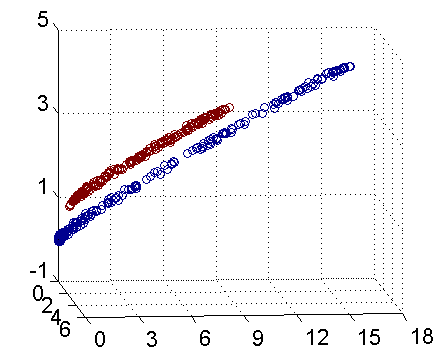
核函数的价值在于它虽然也是将特征进行从低维到高维的转换,但核函数事先在低维上进行计算,而将实质上的分类效果表现在了高维上,避免了直接在高维空间中的复杂计算。
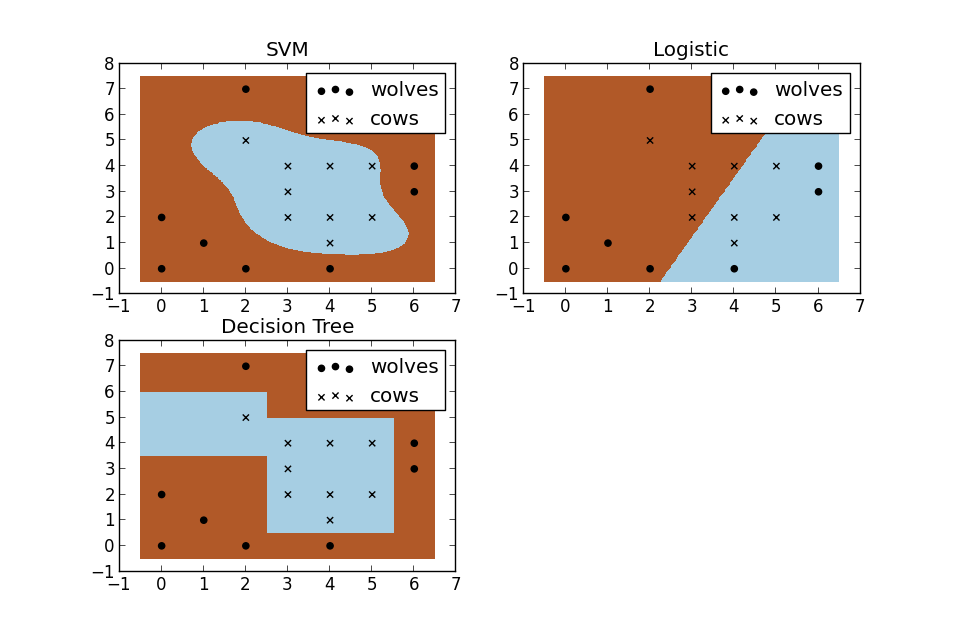
常见分类模型
- 标题: 数据挖掘-SVM
- 作者: Spike Zhang
- 创建于 : 2017-03-09 22:06:30
- 更新于 : 2024-07-13 09:46:17
- 链接: https://chaosbynn.github.io/2017/03/09/数据挖掘-SVM/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
评论