
数据挖掘-K-Means
类内数据点越近越好,类间数据点越远越好。
| 属性 | 描述 |
|---|---|
| 优点 | 容易实现 |
| 缺点 | 可能收敛到局部最小值,在大规模数据集上收敛较慢 |
| 适用 | 数值型 |
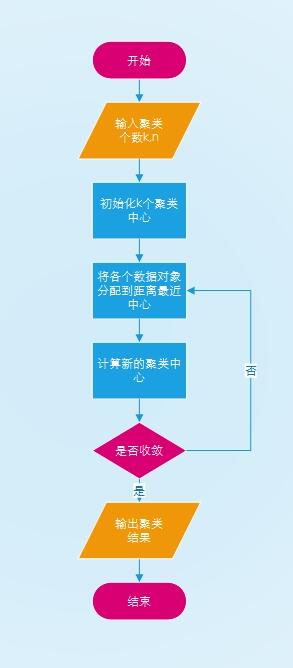
输入:分类个数k,包含在n个数据对象的数据集
输出:k个聚类
步骤:
- 从n个数据对象中任意选取k个对象作为初始聚类中心
- 分别计算每个对象到各个聚类中心距离,把对象分配到距离最近的聚类中
- 所有对象分配后,重新计算k个聚类的中心
- 与前一次计算得到k个聚类中心比较,如果聚类中心发生变化,转步骤2,否则转步骤
- 得出结果
- 标题: 数据挖掘-K-Means
- 作者: Spike Zhang
- 创建于 : 2017-03-21 22:02:41
- 更新于 : 2024-07-13 09:46:17
- 链接: https://chaosbynn.github.io/2017/03/21/数据挖掘-K-Means/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
评论