Log 如何打印好一份日志
写不好日志的程序员,就像不会写病历的医生
打日志远不止是“把变量打印出来”那么简单。 它是一项需要深刻理解业务、具备前瞻性思维、并兼顾性能与可维护性的工程实践。一个经验丰富的开发者打出的日志,往往能在系统上线数月甚至数年后,成为排查问题、配置监控、分析报表的关键依据。
好的日志,是写给未来的自己和团队看的。
格式统一
反例
1 | log.info("start process"); |
无上下文, 无时间戳, 没有更多有价值信息
正解
1 | <!-- logback.xml核心配置 --> |
在logback.xml中统一配置了日志的时间格式、tradeId,线程、等级、日志详情都信息。
日志的格式统一了,更方便点位问题。
异常必带堆栈
反例 (同事看了想打人)
1 | try { |
出现异常了,日志中没打印任何的异常堆栈信息。
相当于自己把异常吃掉了。
非常不好排查问题。
正解
1 | log.error("订单处理异常 orderId={}", orderId, e); // e必须存在! |
日志中记录了出现异常的订单号orderId和异常的堆栈信息e。
有必要时还需打印堆栈链中的cauze信息
级别合理
反例

1 | log.debug("用户余额不足 userId={}", userId); // 业务异常应属WARN |
接口响应稍慢,打印了error级别的日志,显然不太合理。
正常情况下,普通超时属INFO级别。
正解
error:错误日志,指比较严重的错误,对正常业务有影响,需要运维配置监控的;warn:警告日志,一般的错误,对业务影响不大,但是需要开发关注;info:信息日志,记录排查问题的关键信息,如调用时间、出参入参等等;debug:用于开发DEBUG的,关键逻辑里面的运行时数据;trace:最详细的信息,一般这些信息只记录到日志文件中。
参数完整
反例 (让查问题的人无语)
1 | log.info("用户登录失败"); |
上面这个日志只打印了“用户登录失败”这个文案。
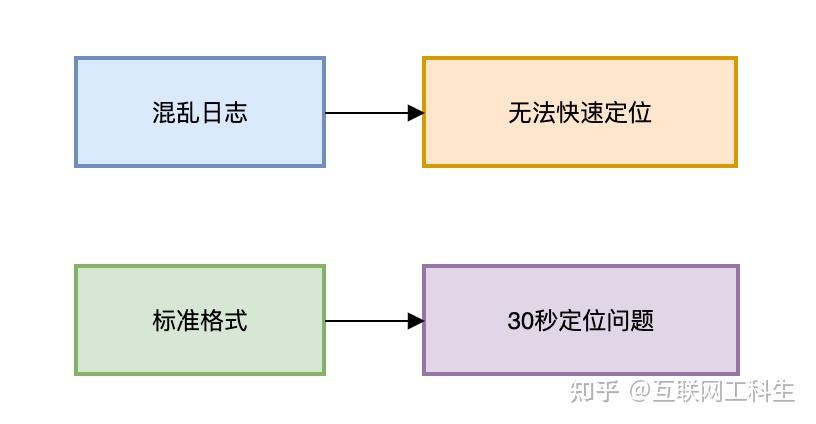
谁在哪登录失败?
正解
日志要打印出方法的入参、出参
我们并不需要打印很多很多日志,只需要打印可以快速定位问题的有效日志。有效的日志,是甩锅的利器!
1 | log.warn("用户登录失败 username={}, clientIP={}, failReason={}", username, clientIP, "密码错误次数超限"); |
登录失败的业务场景,需要记录哪个用户,ip是多少,在什么时间,登录失败了,失败的原因是什么。
时间在logback.xml中统一配置了格式。
这样才方便快速定位问题:
合理的打印时机
遇到if…else…等条件时,每个分支首行都尽量打印日志
当你碰到if…else…或者switch这样的条件时,可以在分支的首行就打印日志,这样排查问题时,就可以通过日志,确定进入了哪个分支,代码逻辑更清晰,也更方便排查问题了。
1 | if(user.isVip()){ |
数据脱敏
在记录的日志中,需要对一下用户的个人敏感数据做脱敏处理。
1 | // 脱敏工具类 |
异步保性能
问题复现某次秒杀活动中直接同步写日志,导致大量线程阻塞:
1 | log.info("秒杀请求 userId={}, itemId={}", userId, itemId); |
高并发下IO阻塞。
致命伤害分析:
- 同步写日志导致线程上下文切换频繁
- 磁盘IO成为系统瓶颈
- 高峰期日志打印耗时占总RT的25%
正解 四步配置
步骤1:logback.xml配置异步通道
1 | <!-- 异步Appender核心配置 --> |
步骤2:日志输出优化代码
1 | // 无需前置判断,框架自动处理 |
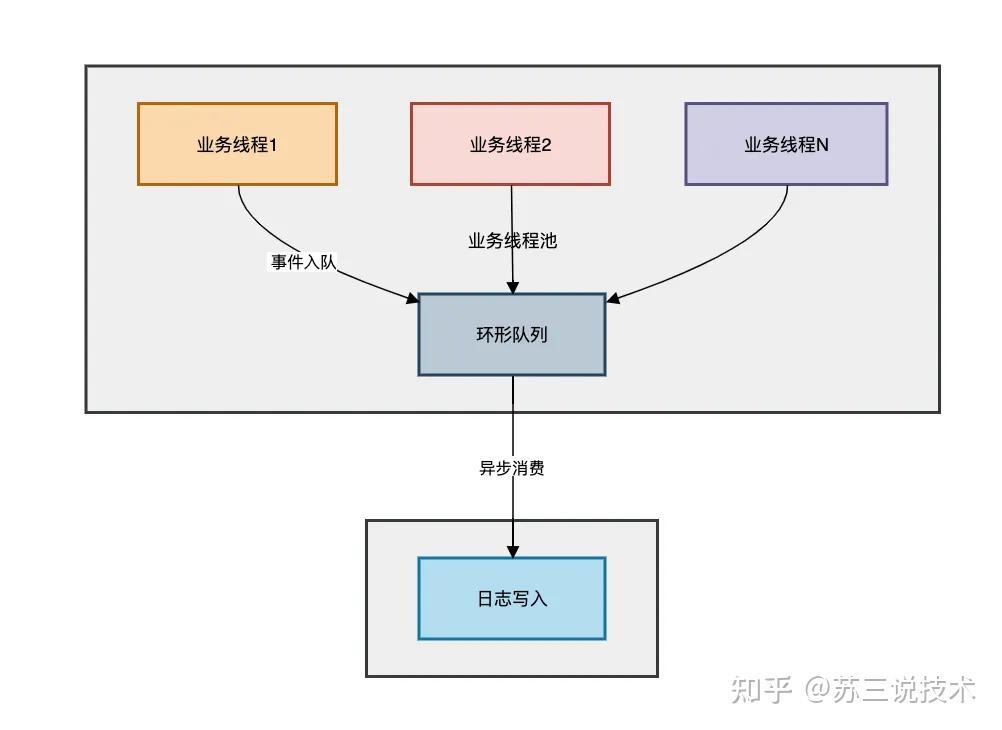
步骤3:性能关键参数公式
最大内存占用 ≈ 队列长度 × 平均单条日志大小
推荐队列深度 = 峰值TPS × 容忍最大延迟(秒)
例如:10000 TPS × 0.5s容忍 ⇒ 5000队列大小
步骤4:日志内容优化
不要使用
e.printStackTrace()
1 | // 反例 |
理由
e.printStackTrace()打印出的堆栈日志跟业务代码日志是交错混合在一起的,通常排查异常日志不太方便e.printStackTrace()语句产生的字符串记录的是堆栈信息,如果信息太长太多,字符串常量池所在的内存块没有空间了,即内存满了,那么,用户的请求就卡住了
风险规避策略
- 防队列堆积:监控队列使用率,达80%触发告警
- 防OOM:严格约束大对象toString()的调用
- 紧急逃生:预设JMX接口用于快速切换同步模式
避免重复打印日志
避免重复打印日志,酱紫会浪费磁盘空间。如果你已经有一行日志清楚表达了意思,避免再冗余打印
1 | if(user.isVip()){ |
日志文件分离
- 我们可以把不同类型的日志分离出去,比如
access.log,或者error级别error.log,都可以单独打印到一个文件里面。 - 当然,也可以根据不同的业务模块,打印到不同的日志文件里,这样我们排查问题和做数据统计的时候,都会比较方便啦。
链路追踪
混沌场景
跨服务调用无法关联日志。我们需要有链路追踪方案。
全链路方案
1 | // 拦截器注入traceId |
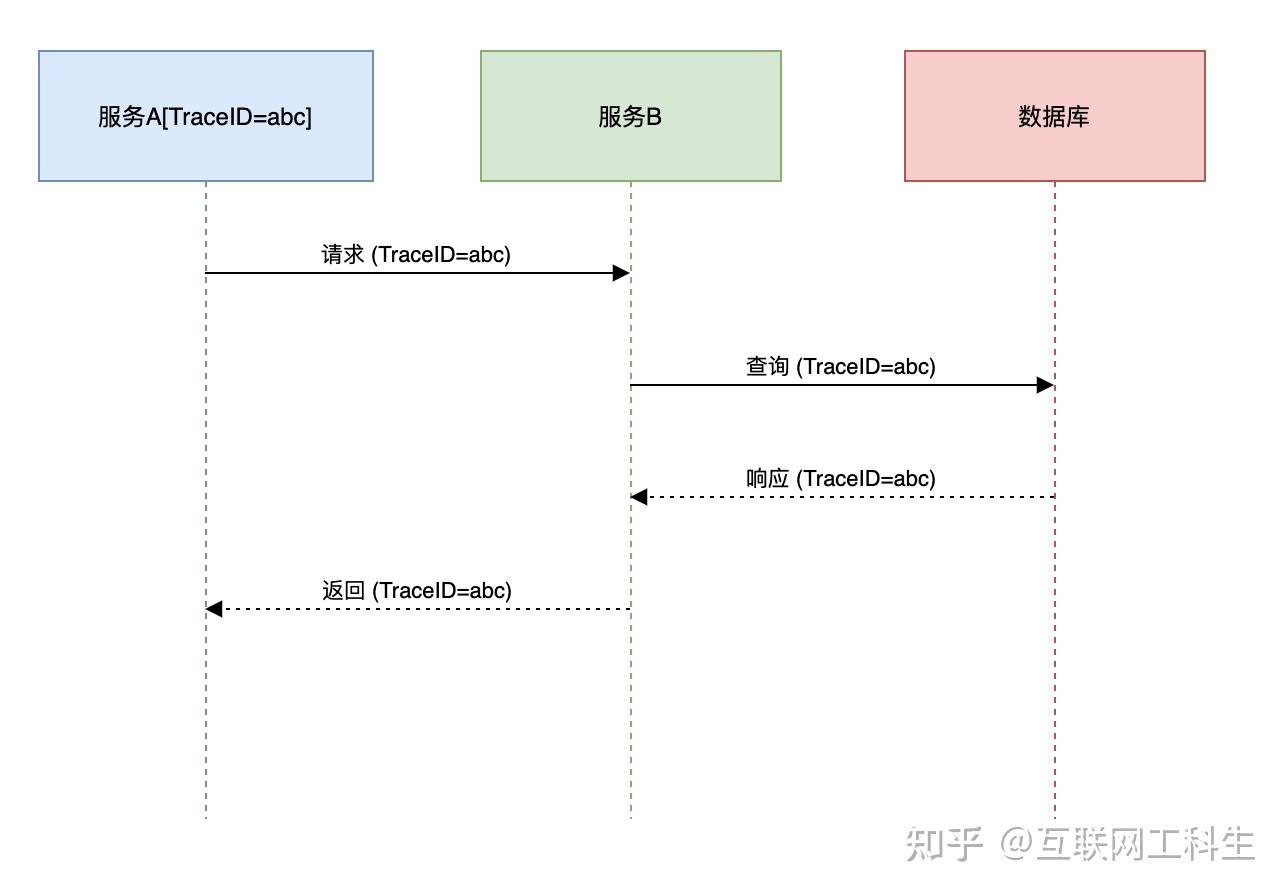
可以在MDC中设置traceId。
后面可以通过traceId全链路追踪日志。
动态调参
半夜重启的痛
线上问题需要临时开DEBUG日志,比如:查询用户的某次异常操作的日志。
热更新方案
Spring Actuator 支持动态调整日志级别。可以具体到某个类或包。
1 | curl -X POST "http://localhost:8081/actuator/loggers/ROOT" -H "Content-Type: application/json" -d '{"configuredLevel": "DEBUG"}' |
有时候我们需要临时打印DEBUG日志,这就需要有个动态参数控制了。
否则每次调整打印日志级别都需要重启服务,可能会影响用户的正常使用。
1 | journey |
结构化存储
混沌日志
1 | 用户购买了苹果手机 订单号1001 金额8999 |
上面的日志拼接成了一个字符串,虽说中间有空格分隔了,但哪些字段对应了哪些值,看起来不是很清楚。
我们在存储日志的时候,需要做结构化存储,方便快速的查询和搜索。
机器友好式日志
1 | { |
这里使用了json格式存储日志。
日志中的数据一目了然。
智能监控
最失败案例
某次用户开通会员操作,错误日志堆积3天才被发现,黄花菜都凉了。
ELK监控方案
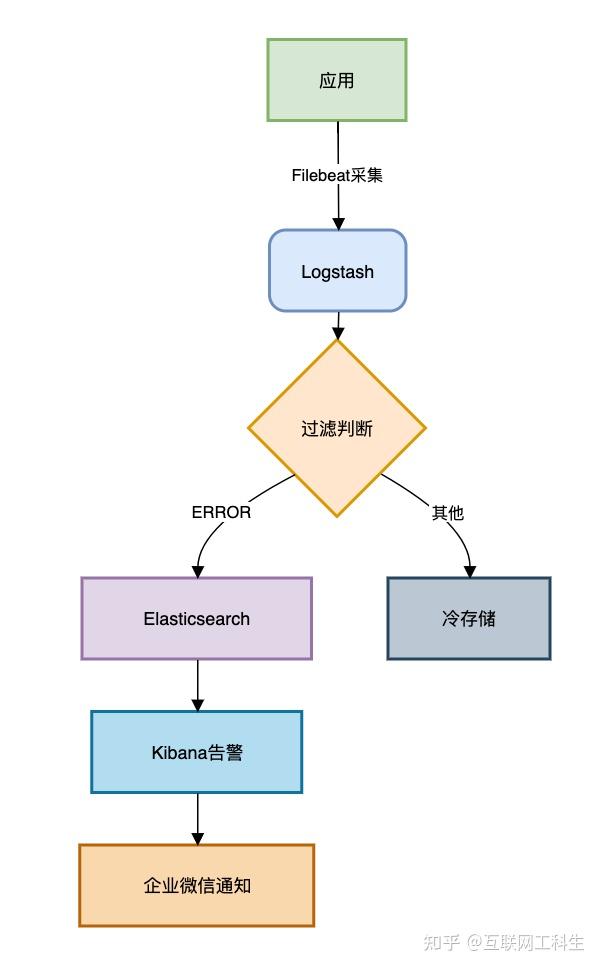
报警规则示例:
1 | ERROR日志连续5分钟 > 100条 → 电话告警 |
最后的灵魂拷问:下次线上故障时,你的日志能让新人5分钟定位问题吗?

- 标题: Log 如何打印好一份日志
- 作者: Spike Zhang
- 创建于 : 2026-01-12 10:20:03
- 更新于 : 2026-01-12 10:31:23
- 链接: https://chaosbynn.github.io/2026/01/12/Log-如何打印好一份日志/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。